A Stable Score Can Still Hide Unstable Evidence
What stress-testing AVS Rubric across three companies taught me about building an AI-native trust infrastructure diagnostic
If you're building an AI-native product, your public surface is doing more evaluation work than you think.
Before a buyer ever books a demo, they're scanning your pricing page, your docs, your trust surfaces — trying to answer questions like: Will this product solve my problem? How will I benefit from it compared to the alternatives? Can I predict how this product behaves, what it will cost, and where the risk sits?
That evaluation is also happening faster and earlier than it used to. Pricing architecture is getting more complex — credit-based models, hybrid tiers, AI add-on premiums — at the exact moment buyers are expecting more transparency. And increasingly, the first pass isn't a human at all. AI-assisted research, answer engines, and procurement tools are pre-screening vendor surfaces before a buyer invests real attention.
When those signals are incomplete or contradictory, buyers hesitate. And you won't see it in your data until it shows up as a stalled evaluation, pricing confusion, or churn.
AVS Rubric exists to diagnose whether that trust infrastructure is legible before the gap slows growth. This week, while stress-testing it across Beautiful.ai, Hex, and ZoomInfo, I learned that diagnosing trust gaps requires something harder than good scoring logic.
It requires evidence integrity.
Beautiful.ai made the problem easiest to see
Across eight successive runs of AVS Rubric analysis, the headline score held at 11/16 (68%) in seven of them. That looked stable, but during my manual auditing, I discovered it wasn't.
Each run reflected a successive fix to the rubric. Under that apparently stable score, the evidence shifted materially:
- Early runs still carried weak or misleading commercial logic
- One run dropped the pricing page entirely from the evidence set — collapsing three dimension scores and generating a recommendation to publish a pricing page that already existed
- A later run pulled in a
/template-categories/plans-strategiespage that contained a refund policy directly contradicting the live pricing page. The template page said no refunds after the billing cycle commenced. The actual pricing page offers partial refunds within 24 hours for annual plans - Only the eighth run resolved all tracked issues at the same time
The score didn't move. The trustworthiness of what sat underneath it shifted.
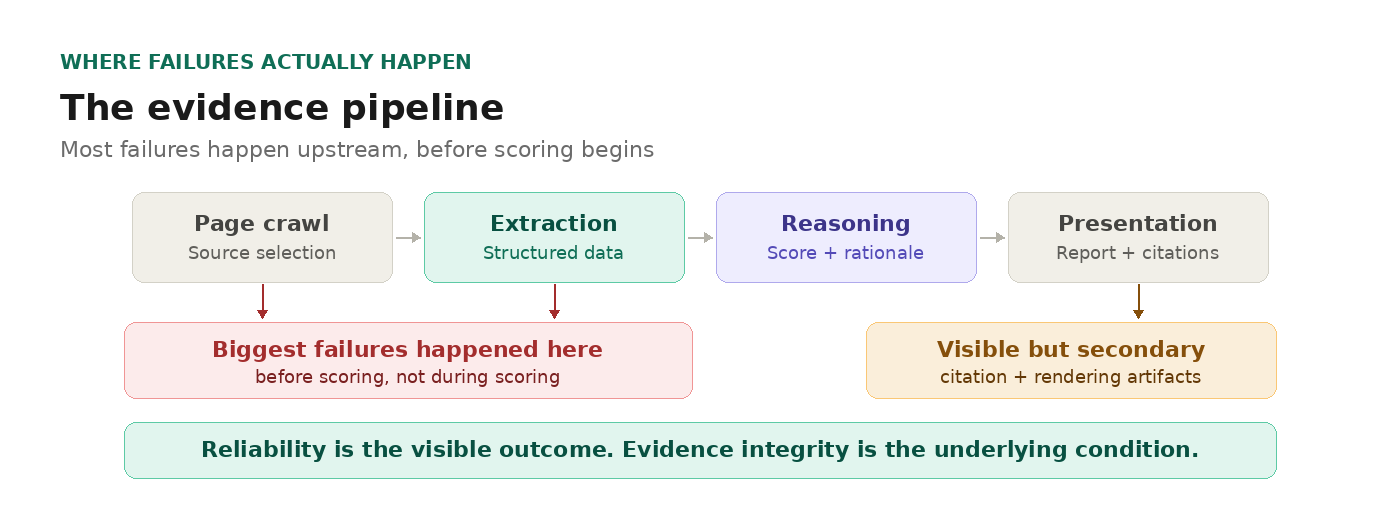
The same failure pattern showed up across all three companies
The biggest failures happened before scoring. They fell into three classes:
Evidence contamination. Wrong pages entered the evidence set — structured, official-looking, clearly from the company's domain, but not the right source of truth. ZoomInfo's biometric privacy notice was interpreted as a customer-facing safety rail. Hex had a citation formatted like real structured data, specific enough to seem authoritative, with no traceable URL. These errors are worse than obvious noise, because clean but wrong evidence gets trusted.
Citation and rendering artifacts. A citation that rendered as a garbled markdown fragment instead of a clean reference. A source note that looked like it was left in by accident. These are the kinds of artifacts that come with building on LLMs — the model generates structured output, but not always cleanly. None of these changed the score, but they made the evidence trail harder to trust. And if a founder can't trust the presentation, they won't trust the reasoning behind it. That's why treating these artifacts as product-quality issues — not cosmetic ones — matters for any AI-native system that claims to be evidence-based.
Low-signal page crowding. Irrelevant pages consumed crawl slots that should have gone to pricing, FAQ, billing, and comparison pages. In Hex's case, three crawl slots were wasted on a sitemap XML file, a single database integration page, and a product launch event page. None contaminated the scores, but they displaced pages that had strengthened evidence in earlier versions.
Different companies. Different surfaces. Same upstream problem: the evidence entering the system did not deserve to be reasoned over.

The most important improvements came from the evidence pipeline, not the model
The fixes that mattered most this week did not come from making the model smarter. They came from making the evidence pipeline more disciplined with guardrails.
Page-level exclusion rules. I added URL-pattern blocklists to prevent template pages, legal boilerplate, sitemaps, and category pages from entering the evidence pool. The Beautiful.ai template page contamination — the one that contradicted the actual refund policy — was the trigger. Before this change, any page on a company's domain could enter the evidence set if it looked relevant to the crawler. Now, known low-signal page types are excluded before analysis begins.
Intent-weighted page priority. Not all pages are equal, and the crawler now reflects that. Pricing pages, FAQ pages, and billing pages are weighted highest in discovery — pricing pages receive the strongest priority signal, with FAQ and billing pages close behind. Comparison, solutions, and case study pages get reserved slots. Generic product pages rank lower. This directly addressed the Hex problem: crawl slots wasted on integration docs and event pages instead of the surfaces that carry commercial signals. When the crawl-page cap forces tradeoffs, the pages that matter most to a buyer's evaluation are now selected first.
Source validation before extraction gets trusted. This was the most important technical lesson: structured extraction is a force multiplier, and it multiplies both signal and noise. When it points at the right page, plans, limits, and packaging logic become easier to reason over. When it points at the wrong page, the bad source becomes more legible and more persuasive than it deserves to be. I added nine evidence quality rules that reject boilerplate, vague slogans, legal text, and template content before the extraction output gets scored. Machine-extracted JSON is now treated as context only, not as direct quotes — preventing noise amplification from accordion and table extraction artifacts.
Manual audit of the evidence trail. Some of the worst failures would have passed if I had only looked at the final score and rationale. They became obvious only when I reviewed the evidence trail line by line — half through my own inspection, half by using Claude to do detailed comparison and analysis between successive runs. The Beautiful.ai pricing page drop, the ZoomInfo legal page misread, the Hex phantom citation — all were caught through this process, not through scoring logic. That is the kind of work that does not look dramatic from the outside, but it is where reliability gets built.
Trust infrastructure diagnostics need auditable evidence, not just plausible output
This is the broader point behind the week's work.
ValueTempo is not trying to produce another generic AI output. The ambition is narrower and more useful: to build an AI-native trust infrastructure diagnostic that helps founders and GTM leaders see whether their publicly observable signals make their product legible enough to support growth.
That is a different question from whether your pricing page is good, or how you compare to competitors, or what an answer engine says about you.
The real question is: can a buyer predict how this product behaves, what it may cost, and where the risk sits — before they commit more attention, budget, or trust?
If the evidence base is weak, the diagnostic may still sound smart. It just does not deserve to be trusted yet.
Stable numbers are not enough. The real bar is evidence integrity.
Test your own surface
Here's a quick test: pull up your own product's public surface — pricing page, docs, trust center — and ask yourself whether a buyer evaluating your product for the first time could answer these questions from what's visible:
- Will this product solve my specific problem?
- Why should I choose this over the alternatives?
- What will it cost at twice my current usage?
- What happens if something goes wrong?
If any of those answers require guessing, that's a trust gap.
If you want to see how those gaps score across the full Trust Stack, run your product through AVS Rubric at app.valuetempo.com.